Resumo : neste tutorial, você aprenderá como usar Django Group By com funções agregadas para calcular agregação para grupos.
Introdução ao Grupo Django Por
A cláusula SQL GROUP BYagrupa as linhas retornadas por uma consulta em grupos. Normalmente, você usa funções agregadas como contagem, mínimo, máximo, média e soma com a GROUP BYcláusula para retornar um valor agregado para cada grupo.
Aqui está o uso básico da GROUP BYcláusula em uma SELECTdeclaração:
SELECT column_1, AGGREGATE(column_2)
FROM table_name
GROUP BY column1;Linguagem de código: SQL (linguagem de consulta estruturada) ( sql )No Django, você pode usar o annotate()método para values()aplicar a agregação em grupos como este:
(Entity.objects
.values('column_2')
.annotate(value=AGGREGATE('column_1'))
)Linguagem de código: Python ( python )Nesta sintaxe;
values('column_2')– passe a coluna que deseja agrupar aovalues()método.annotate(value=AGGREGATE('column_1'))– especifique o que agregar noannotate()método.
Observe que a ordem de chamada values()e annotates()importa. Se você não chamar o values()método primeiro e annotate()depois, a expressão não produzirá resultados agregados.
Grupo Django por exemplos
Usaremos os modelos Funcionário e Departamento do HRaplicativo para demonstração. Os modelos Emloyeee Departmentsão mapeados para as tabelas hr_employeee hr_departmentno banco de dados:
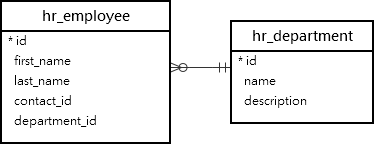
1) Django Group By com exemplo de contagem
O exemplo a seguir usa o método values()and annotate()para obter o número de funcionários por departamento:
>>> (Employee.objects
... .values('department')
... .annotate(head_count=Count('department'))
... .order_by('department')
... )
SELECT "hr_employee"."department_id",
COUNT("hr_employee"."department_id") AS "head_count"
FROM "hr_employee"
GROUP BY "hr_employee"."department_id"
ORDER BY "hr_employee"."department_id" ASC
LIMIT 21
Execution time: 0.001492s [Database: default]
<QuerySet [{'department': 1, 'head_count': 30}, {'department': 2, 'head_count': 40}, {'department': 3, 'head_count': 28}, {'department': 4, 'head_count': 29}, {'department': 5, 'head_count': 29}, {'department': 6, 'head_count': 30}, {'department': 7, 'head_count': 34}]>Linguagem de código: Python ( python )Como funciona.
Primeiro, agrupe os funcionários por departamento usando o values()método:
values('department')Linguagem de código: Python ( python )Em segundo lugar, aplique Count()a cada grupo:
annotate(head_count=Count('department'))Linguagem de código: Python ( python )Terceiro, classifique os objetos por QuerySetdepartamento:
order_by('department')Linguagem de código: Python ( python )Nos bastidores, o Django executa a SELECTinstrução com a GROUP BYcláusula:
SELECT "hr_employee"."department_id",
COUNT("hr_employee"."department_id") AS "head_count"
FROM "hr_employee"
GROUP BY "hr_employee"."department_id"
ORDER BY "hr_employee"."department_id" ASC
LIMIT 21
Linguagem de código: SQL (linguagem de consulta estruturada) ( sql )2) Django Group By com exemplo de soma
Da mesma forma, você pode usar o Sum()agregado para calcular o salário total dos funcionários de cada departamento:
>>> (Employee.objects
... .values('department')
... .annotate(total_salary=Sum('salary'))
... .order_by('department')
... )
SELECT "hr_employee"."department_id",
SUM("hr_employee"."salary") AS "total_salary"
FROM "hr_employee"
GROUP BY "hr_employee"."department_id"
ORDER BY "hr_employee"."department_id" ASC
LIMIT 21
Execution time: 0.000927s [Database: default]
<QuerySet [{'department': 1, 'total_salary': Decimal('3615341.00')}, {'department': 2, 'total_salary': Decimal('5141611.00')}, {'department': 3, 'total_salary': Decimal('3728988.00')}, {'department': 4, 'total_salary': Decimal('3955669.00')}, {'department': 5, 'total_salary': Decimal('4385784.00')}, {'department': 6, 'total_salary': Decimal('4735927.00')}, {'department': 7, 'total_salary': Decimal('4598788.00')}]>
Linguagem de código: Python ( python )3) Django Group By com exemplo de Min, Max e Avg
O exemplo a seguir aplica diversas funções agregadas a grupos para obter o salário mais baixo, médio e mais alto dos funcionários em cada departamento:
>>> (Employee.objects
... .values('department')
... .annotate(
... min_salary=Min('salary'),
... max_salary=Max('salary'),
... avg_salary=Avg('salary')
... )
... .order_by('department')
... )
SELECT "hr_employee"."department_id",
MIN("hr_employee"."salary") AS "min_salary",
MAX("hr_employee"."salary") AS "max_salary",
AVG("hr_employee"."salary") AS "avg_salary"
FROM "hr_employee"
GROUP BY "hr_employee"."department_id"
ORDER BY "hr_employee"."department_id" ASC
LIMIT 21
Execution time: 0.001670s [Database: default]
<QuerySet [{'department': 1, 'min_salary': Decimal('45427.00'), 'max_salary': Decimal('149830.00'), 'avg_salary': Decimal('120511.366666666667')}, {'department':
2, 'min_salary': Decimal('46637.00'), 'max_salary': Decimal('243462.00'), 'avg_salary': Decimal('128540.275000000000')}, {'department': 3, 'min_salary': Decimal('40762.00'), 'max_salary': Decimal('248265.00'), 'avg_salary': Decimal('133178.142857142857')}, {'department': 4, 'min_salary': Decimal('43000.00'), 'max_salary':
Decimal('238016.00'), 'avg_salary': Decimal('136402.379310344828')}, {'department': 5, 'min_salary': Decimal('42080.00'), 'max_salary': Decimal('246403.00'), 'avg_salary': Decimal('151233.931034482759')}, {'department': 6, 'min_salary': Decimal('58356.00'), 'max_salary': Decimal('248312.00'), 'avg_salary': Decimal('157864.233333333333')}, {'department': 7, 'min_salary': Decimal('40543.00'), 'max_salary': Decimal('238892.00'), 'avg_salary': Decimal('135258.470588235294')}]>Linguagem de código: Python ( python )4) Grupo Django com exemplo de junção
O exemplo a seguir usa os métodos values()e annotate()para obter o número de funcionários por departamento:
>>> (Department.objects
... .values('name')
... .annotate(
... head_count=Count('employee')
... )
... )
SELECT "hr_department"."name",
COUNT("hr_employee"."id") AS "head_count"
FROM "hr_department"
LEFT OUTER JOIN "hr_employee"
ON ("hr_department"."id" = "hr_employee"."department_id")
GROUP BY "hr_department"."name"
LIMIT 21
Execution time: 0.001953s [Database: default]
<QuerySet [{'name': 'Marketing', 'head_count': 28}, {'name': 'Finance', 'head_count': 29}, {'name': 'SCM', 'head_count': 29}, {'name': 'GA', 'head_count': 30}, {'name': 'Sales', 'head_count': 40}, {'name': 'IT', 'head_count': 30}, {'name': 'HR', 'head_count': 34}]>Linguagem de código: Python ( python )Como funciona.
values('name')– agrupa o departamento por nome.annotate(headcount=Count('employee'))– conta funcionários em cada departamento.
Nos bastidores, Django usa a LEFT JOINpara unir hr_departmenttabela com hr_employeetabela e aplicar a COUNT()função a cada grupo.
Grupo Django com tendo
Para aplicar uma condição aos grupos, você usa o filter()método. Por exemplo, o seguinte usa o filter()método para obter o departamento com número de funcionários superior a 30:
>>> (Department.objects
... .values('name')
... .annotate(
... head_count=Count('employee')
... )
... .filter(head_count__gt=30)
... )
SELECT "hr_department"."name",
COUNT("hr_employee"."id") AS "head_count"
FROM "hr_department"
LEFT OUTER JOIN "hr_employee"
ON ("hr_department"."id" = "hr_employee"."department_id")
GROUP BY "hr_department"."name"
HAVING COUNT("hr_employee"."id") > 30
LIMIT 21
Execution time: 0.002893s [Database: default]
<QuerySet [{'name': 'Sales', 'head_count': 40}, {'name': 'HR', 'head_count': 34}]>
Linguagem de código: Python ( python )Nos bastidores, o Django usa a HAVINGcláusula para filtrar o grupo com base na condição que passamos para o filter()método:
SELECT "hr_department"."name",
COUNT("hr_employee"."id") AS "head_count"
FROM "hr_department"
LEFT OUTER JOIN "hr_employee"
ON ("hr_department"."id" = "hr_employee"."department_id")
GROUP BY "hr_department"."name"
HAVING COUNT("hr_employee"."id") > 30
Linguagem de código: Python ( python )Resumo
- Use
values()umannotate()método para agrupar linhas em grupos. - Use
filter()para adicionar condições a grupos de filtros.