Resumo : neste tutorial, você aprenderá como usar o analisador de texto completo MySQL ngram para oferecer suporte a pesquisas de texto completo para idiomas ideográficos, como chinês, japonês e coreano.
Introdução ao analisador de texto completo MySQL ngram
O analisador de texto completo integrado do MySQL determina o início e o fim das palavras usando espaços em branco como delimitadores.
No entanto, no caso de línguas ideográficas como o chinês, o japonês e o coreano, surge uma limitação, uma vez que estas línguas não utilizam delimitadores de palavras.
Para resolver esse problema, o MySQL forneceu o analisador de texto completo ngram.
A partir da versão 5.7.6, o MySQL incluiu o analisador de texto completo ngram como um plugin de servidor integrado, o que significa que o MySQL carrega este plugin automaticamente quando o servidor de banco de dados MySQL é iniciado.
MySQL suporta analisador de texto completo ngram para mecanismos de armazenamento InnoDB e MyISAM.
Por definição, um ngram é uma sequência contígua de caracteres de uma sequência de texto. A função principal do analisador de texto completo ngram é tokenizar uma sequência de texto em sequências contíguas de n caracteres.
O seguinte ilustra como o analisador de texto completo ngram tokeniza uma sequência de texto para diferentes valores de n:
n = 1: 'm','y','s','q','l'
n = 2: 'my', 'ys', 'sq','ql'
n = 3: 'mys', 'ysq', 'sql'
n = 4: 'mysq', 'ysql'
n = 5: 'mysql'Linguagem de código: JavaScript ( javascript )Criando índices FULLTEXT com analisador ngram
Para criar um FULLTEXTíndice que usa um analisador de texto completo ngram, você adiciona WITH PARSER ngramna instrução CREATE TABLE, ALTER TABLEou CREATE INDEX. Considere o seguinte exemplo:
Primeiro, crie um novo banco de dados chamado teste:
CREATE DATABASE test;Segundo, crie uma nova tabela chamada postscom um índice de texto completo que inclua as colunas titlee :body
CREATE TABLE posts (
id INT PRIMARY KEY AUTO_INCREMENT,
title VARCHAR(255),
body TEXT,
FULLTEXT ( title , body ) WITH PARSER NGRAM
);Segundo, altere o conjunto de caracteres para utf8mb4usar a SET NAMESinstrução:
SET NAMES utf8mb4;Linguagem de código: SQL (linguagem de consulta estruturada) ( sql )Terceiro, insira uma nova linha na poststabela:
INSERT INTO posts(title,body)
VALUES('MySQL全文搜索','MySQL提供了具有许多好的功能的内置全文搜索'),
('MySQL教程','学习MySQL快速,简单和有趣');Linguagem de código: SQL (linguagem de consulta estruturada) ( sql )Por fim, mostre como o ngram tokeniza o texto usando as seguintes instruções:
SET
GLOBAL innodb_ft_aux_table = "test/posts";
SELECT
*
FROM
information_schema.innodb_ft_index_cache
ORDER BY
doc_id,
position;
Linguagem de código: SQL (linguagem de consulta estruturada) ( sql )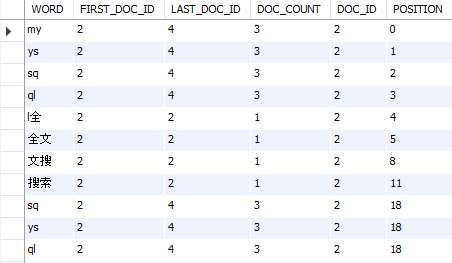
Esta consulta é valiosa para fins de solução de problemas. Por exemplo, se uma palavra não estiver incluída nos resultados da pesquisa, ela poderá não ser indexada por ser uma palavra irrelevante ou por algum outro motivo.
Configurando o tamanho do token ngram
Conforme visto no exemplo anterior, o tamanho do token padrão (n) para ngram é 2. Para modificar o tamanho do token, você pode usar a ngram_token_sizeopção de configuração, que aceita valores entre 1 e 10.
Observe que um tamanho de token menor cria um índice de pesquisa de texto completo menor e permite uma pesquisa mais rápida.
Por ngram_token_sizeser uma variável somente leitura, você só pode definir seu valor usando duas opções:
Primeiro, defina ngram_token_size quando o servidor de banco de dados for iniciado:
mysqld --ngram_token_size=1Linguagem de código: SQL (linguagem de consulta estruturada) ( sql )Segundo, defina ngram_token_size no arquivo de configuração:
[mysqld]
ngram_token_size=1Linguagem de código: SQL (linguagem de consulta estruturada) ( sql )pesquisa de frase do analisador ngram
MySQL converte uma pesquisa de frase em pesquisas de frase ngram. Por exemplo, "abc"é convertido em "ab bc", que retorna documentos que contêm "ab bc"e "abc".
O exemplo a seguir mostra como pesquisar a frase 搜索na poststabela:
SELECT
id, title, body
FROM
posts
WHERE
MATCH (title , body) AGAINST ('搜索' );
Linguagem de código: SQL (linguagem de consulta estruturada) ( sql )
Processando resultados de pesquisa com ngram
Modo de linguagem natural
Nas NATURAL LANGUAGE MODEpesquisas, o termo de pesquisa é convertido em uma união de valores ngram. Suponha que o tamanho do token seja 2 ou bigrama, o termo de pesquisa mysqlseja convertido para my ys sqe ql.
SELECT
*
FROM
posts
WHERE
MATCH (title , body)
AGAINST ('简单和有趣' IN natural language MODE);
Linguagem de código: SQL (linguagem de consulta estruturada) ( sql )
Modo booleano
Nas BOOLEAN MODEpesquisas, o termo de pesquisa é convertido em uma pesquisa de frase ngram. Por exemplo:
SELECT
*
FROM
posts
WHERE
MATCH (title , body)
AGAINST ('简单和有趣' IN BOOLEAN MODE);
Linguagem de código: SQL (linguagem de consulta estruturada) ( sql )pesquisa curinga ngram
O índice ngram FULLTEXTcontém apenas n-gramas e, portanto, não identifica o início dos termos. Como resultado, ao realizar pesquisas curinga, você poderá obter resultados inesperados.
As seguintes regras são aplicadas à pesquisa curinga usando FULLTEXTíndices de pesquisa ngram:
Se o termo do prefixo no curinga for menor que o tamanho do token ngram, a consulta retornará todos os documentos que contêm tokens ngram começando com o termo do prefixo. Por exemplo:
SELECT
id,
title,
body
FROM
posts
WHERE
MATCH (title , body)
AGAINST ('my*' );
Linguagem de código: SQL (linguagem de consulta estruturada) ( sql )
Caso o termo do prefixo no curinga seja maior que o tamanho do token ngram, o MySQL converterá o termo do prefixo em frases ngram e ignorará o operador curinga. Por exemplo:
SELECT
id,
title,
body
FROM
posts
WHERE
MATCH (title , body)
AGAINST ('mysqld*' );
Linguagem de código: SQL (linguagem de consulta estruturada) ( sql )Neste exemplo, o termo “ mysqld"é convertido em frases ngram: "my" "ys" "sq" "ql" "ld". Portanto todos os documentos que contenham uma destas frases serão retornados.
Tratamento de palavras irrelevantes
O analisador ngram exclui tokens que contêm a palavra irrelevante na lista de palavras irrelevantes.
Suponha que ngram_token_sizeseja 2 e o documento contenha "abc". O analisador ngram irá tokenizar o documento para "ab"e "bc".
Se "b"for uma palavra irrelevante, o ngram excluirá ambos "ab"e "bc"porque contêm "b".
Observe que se o idioma for diferente do inglês, você deverá definir sua própria lista de palavras irrelevantes. Além disso, quaisquer palavras irrelevantes com comprimento maior que ngram_token_sizeserão ignoradas.
Neste tutorial, você aprendeu como usar o analisador de texto completo ngram do MySQL para lidar com pesquisas de texto completo para linguagens ideográficas.